At 9:17 AM UTC on November 18, 2025, millions of internet users woke up to blank screens and error messages — not because of a hack, not because of a power grid failure, but because one company’s network quietly collapsed. Cloudflare, Inc., the San Francisco-based internet performance and security giant, suffered a catastrophic internal failure that took down X, OpenAI’s ChatGPT, and thousands of other websites in a matter of minutes. The cause? A cascading error in Cloudflare’s routing systems that triggered widespread HTTP 500 errors — the digital equivalent of a store’s lights going out, but with no one able to flip the switch.
How the outage unfolded
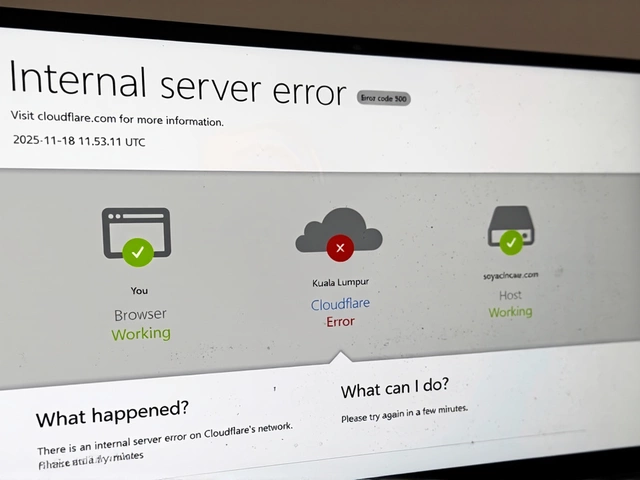
The first signs appeared in monitoring dashboards across Europe and North America. Websites that normally load in under a second began returning blank pages with the cryptic message: “500 Internal Server Error.” By 9:45 AM UTC, the problem had spread globally. Users on X couldn’t post. Developers couldn’t deploy code. E-commerce sites vanished. Even OpenAI’s AI chatbot, usually a marvel of reliability, went dark — a rare moment of silence from a service millions rely on daily.
What made it worse? Cloudflare’s own tools were down. The company’s Dashboard — the control panel used by customers to manage their domains, firewalls, and SSL certificates — became unreachable. So did their API. That meant even if you knew what was wrong, you couldn’t fix it yourself. It was like losing both your car keys and the mechanic’s phone number at the same time.
Global impact: Who got hit hardest?
The outage didn’t discriminate. Small blogs, Fortune 500 companies, SaaS platforms, news outlets — all were affected if they used Cloudflare’s CDN or DNS services. The scale was staggering. Cloudflare serves over 100 million websites, and while not all were impacted, the most visible casualties were the giants: X, OpenAI, and even lesser-known but critical services like payment gateways and authentication providers.
By 11:30 AM UTC, users in Asia reported similar failures. In Sydney, a fintech startup lost 40 minutes of transactions. In Berlin, a digital newspaper couldn’t load its paywall. In São Paulo, an e-learning platform crashed mid-lecture. The ripple effect was real — and silent. No alarms rang. No press releases came out until nearly two hours later.
Cloudflare’s only public statement, posted on their status page and later echoed by TechRadar and Engadget, read: “Cloudflare is aware of, and investigating an issue which impacts multiple customers: Widespread 500 errors, Cloudflare Dashboard and API also…” That’s it. No cause. No ETA. Just a confirmation that the house was on fire — and they were trying to put it out.
Why this outage matters more than most
This wasn’t just another tech glitch. It exposed how much of the modern internet runs on a handful of centralized providers. Cloudflare isn’t a luxury — it’s infrastructure. Think of it like the electrical grid, but for websites. When it fails, everything that plugs into it goes dark.
Compare this to the 2021 Fastly outage, which took down Reddit, Amazon, and The New York Times for 47 minutes. That was bad. This was worse — longer, broader, and with no public explanation. And unlike Fastly, Cloudflare doesn’t just deliver content — it filters attacks, encrypts traffic, and manages identity. When its systems glitch, security fails too.
Worse still, there’s no real backup. Most companies can’t afford to run redundant CDNs across multiple providers. The cost is too high. The complexity, too great. So they bet on Cloudflare. And when Cloudflare stumbles? Everyone falls.
Recovery and what’s next
By 12:30 PM UTC, things began to stabilize. OpenAI restored ChatGPT. X came back online. By 3:00 PM UTC, TechRadar confirmed: “all recovered now.” Engadget noted the same. The lights were back on.
But here’s the thing: we still don’t know what caused it. Cloudflare hasn’t said. No executive has spoken. No engineers have leaked details. That’s not normal. In 2024, Cloudflare had a similar, smaller outage that affected 0.5% of global traffic. They published a full post-mortem within 48 hours. This time? Silence.
That’s the real concern. Not that it happened. But that we don’t know how to prevent it from happening again.
What this means for the average user
If you use the internet — and you do — this outage was a wake-up call. It showed how fragile the digital world really is. One company, one misconfiguration, one line of faulty code, and your morning routine — checking email, reading news, ordering coffee — grinds to a halt.
It’s not just about speed or uptime. It’s about trust. We assume the internet works. We don’t question it. But when it fails, we realize: we’re all just tenants in a building owned by a handful of tech giants. And they don’t always tell us when the foundation cracks.
Frequently Asked Questions
What caused the Cloudflare outage on November 18, 2025?
Cloudflare has not publicly disclosed the root cause. The company confirmed widespread HTTP 500 errors and a failure of its Dashboard and API systems, but offered no technical explanation. Industry analysts suspect a misconfigured routing update or a cascading failure in their Anycast network, but without an official post-mortem, the exact trigger remains unknown.
How long were services down during the outage?
The outage lasted approximately three and a half hours, from around 9:00 AM UTC to 12:30 PM UTC on November 18, 2025. Most major services like X and ChatGPT began recovering by 12:00 PM UTC, with full restoration confirmed by mid-afternoon. This duration was significantly longer than Cloudflare’s previous 2024 incident, which lasted under 30 minutes.
Why couldn’t customers fix the problem themselves?
Because Cloudflare’s own management tools — the Dashboard and API — were offline, customers lost access to their DNS settings, firewall rules, and SSL certificates. Even if they understood the issue, they couldn’t toggle settings, switch providers, or roll back changes. This created a dangerous dependency: the tool meant to fix problems became part of the problem.
Was this the worst Cloudflare outage ever?
It was the most disruptive since 2024, when a misconfiguration briefly affected 0.5% of global internet traffic. This 2025 incident impacted far more high-profile services and lasted longer. While not the largest in terms of raw traffic volume, its effect on critical platforms like ChatGPT and X made it the most visible — and concerning — outage in Cloudflare’s history.
Are other CDN providers at risk of similar failures?
Yes. Every major CDN — including Fastly, Akamai, and Amazon CloudFront — relies on complex, interconnected systems. The 2021 Fastly outage proved that. But Cloudflare’s unique role in security and authentication makes its failures more consequential. The industry is slowly moving toward multi-CDN strategies, but adoption remains low due to cost and complexity.
What should businesses do to avoid being caught in future outages?
Companies should consider hybrid DNS setups — using Cloudflare alongside a secondary provider like Google Cloud DNS or Cloudflare’s own secondary DNS. They should also maintain offline backups of critical DNS records and test failover procedures regularly. For mission-critical services, running redundant infrastructure across multiple clouds can reduce exposure, though it increases cost and complexity.